Acceso a datos¶
Los datos completos a nivel de muestra de cada organismo se pueden descargar desde el propio panel de control de AMRnet usando el botón «Descargar formato de base de datos» en la parte inferior de la página. Además, puede acceder a los datos de AMRnet a través de la API descrita a continuación.
Archivos: Las arquitecturas API tienen 2 opciones desarrolladas para el proyecto que incluyen:
1. Descargar datos a través del cubo¶
Nota
Nombre del organismo para descargar archivos de AWS: Escherichia coli (diarrheagenic) como amrnetdb-Escherichia_coli_ diarrheagenic; Escherichia coli como amrnetdb-Escherichia_coli; Klebsiella pneumoniae como amrnetdb-Klebsiella_pneumoniae; Neisseria gonorrhoeae como amrnetdb-Neisseria_gonorrhoeae; Salmonella (invasiva non-typhoidal) como amrnetdb-Salmonella_enterica_invasive_nontyphoidal; Salmonella (non-typhoidal) como amrnetdb-Salmonella_enterica_nontyphoidal; Shigella como amrnetdb-Shigella_EIEC; Salmonella Typhi como amrnetdb-Salmonella_Typhi
a. Datos de acceso usando el navegador¶
i. Ver archivos disponibles¶
Paso 1: Abra un navegador web (Chrome, Firefox, Safari, etc.).
Paso 2: Navegue a la URL raíz del cubo haciendo clic en https://amrnet.► s.com/.
Paso 3: Esta URL lleva a una representación de texto XML que muestra todos los archivos disponibles en el cubo Amazon S3. El formato XML mostrará información sobre cada archivo, como su clave (nombre), fecha de última modificación, tamaño, etc.
ii. Buscando un organismo específico¶
Paso 1: Utilice la funcionalidad de búsqueda de su navegador (Ctrl-F en Windows/Linux o Cmd-F en Mac).
Paso 2: Escriba el nombre del archivo basado en el organismo que está buscando en el cuadro de búsqueda. Esto resaltará todas las ocurrencias del nombre del organismo en el texto XML, haciendo más fácil localizar el archivo específico asociado con ese organismo.
iii. Descargando un archivo¶
Paso 1: Una vez que encuentre el campo
<Key>que contiene el nombre del archivo en el que está interesado, tenga en cuenta el nombre del archivo.Paso 2: Abra una nueva pestaña en su navegador.
Paso 3: Copie la URL raíz del bucket
https://amrnet..Us.comen la nueva barra de direcciones de la pestaña.Paso 4: Agregar una barra
/al final de la URL, seguido por el contenido del campo<Key>(nombre de archivo).Paso 5: Presione Intro, y su navegador debería iniciar automáticamente la descarga del archivo. Este método ha sido probado para funcionar en Chrome, Firefox y Safari.
O
Copia la siguiente URL y modifica el nombre del organismo agregado al final amrnet-
amrnetdb-Escherichia_coli_ diarrheagenic.csv.gz basado en la lista de organismos dada arriba.
Ejemplo:
https://amrnet.s3.amazonaws.com/amrnet-latest/amrnetdb-Escherichia_coli_ diarrheagenic.csv.gz
b. Acceso a datos usando línea de comandos¶
Paso 1: Abra su terminal.
Paso 2: Utilice el siguiente comando para descargar datos de la URL proporcionada:
curl -O https://amrnet.s3.amazonaws.com/
Del mismo modo, si necesita descargar un archivo específico desde la URL, especificaría el nombre del archivo en la URL. Por ejemplo:
curl -O https://amrnet.s3.amazonaws.com/filename
Ejemplo:
curl -O https://amrnet.s3.amazonaws.com/amrnet-latest/amrnetdb-Escherichia_coli_ diarrheagenic.csv.gz
c. Acceso de datos usando la herramienta S3cmd¶
La herramienta s3cmd es una potente y versátil utilidad de línea de comandos diseñada para interactuar con Amazon S3 (Simple Storage Service). Simplifica tareas tales como navegación, descarga y sincronización de archivos de cubos S3. Esta herramienta es especialmente útil para gestionar grandes conjuntos de datos y automatizar flujos de trabajo que implican el almacenamiento S3.
2. Descargar datos a través de API¶
Enviar un correo electrónico a amrnetdashboard@gmail.com solicitando un token de API.
Ejemplo:
Subject: Request for API Token
I am writing to request an API token for accessing the AMRnet database. Below are the specific details for my request:
Organism Name: Escherichia coli
Recibirá un correo electrónico con todos los detalles necesarios, como: API_TOKEN_KEY, colección, base de datos, fuente de datos.
Una vez que reciba estos detalles utilice el método de abajo para descargar los datos requeridos.
Para descargar datos con fecha y país específicos, añada un filtro.
Código de ejemplo para descargar todos los datos de un organismo:
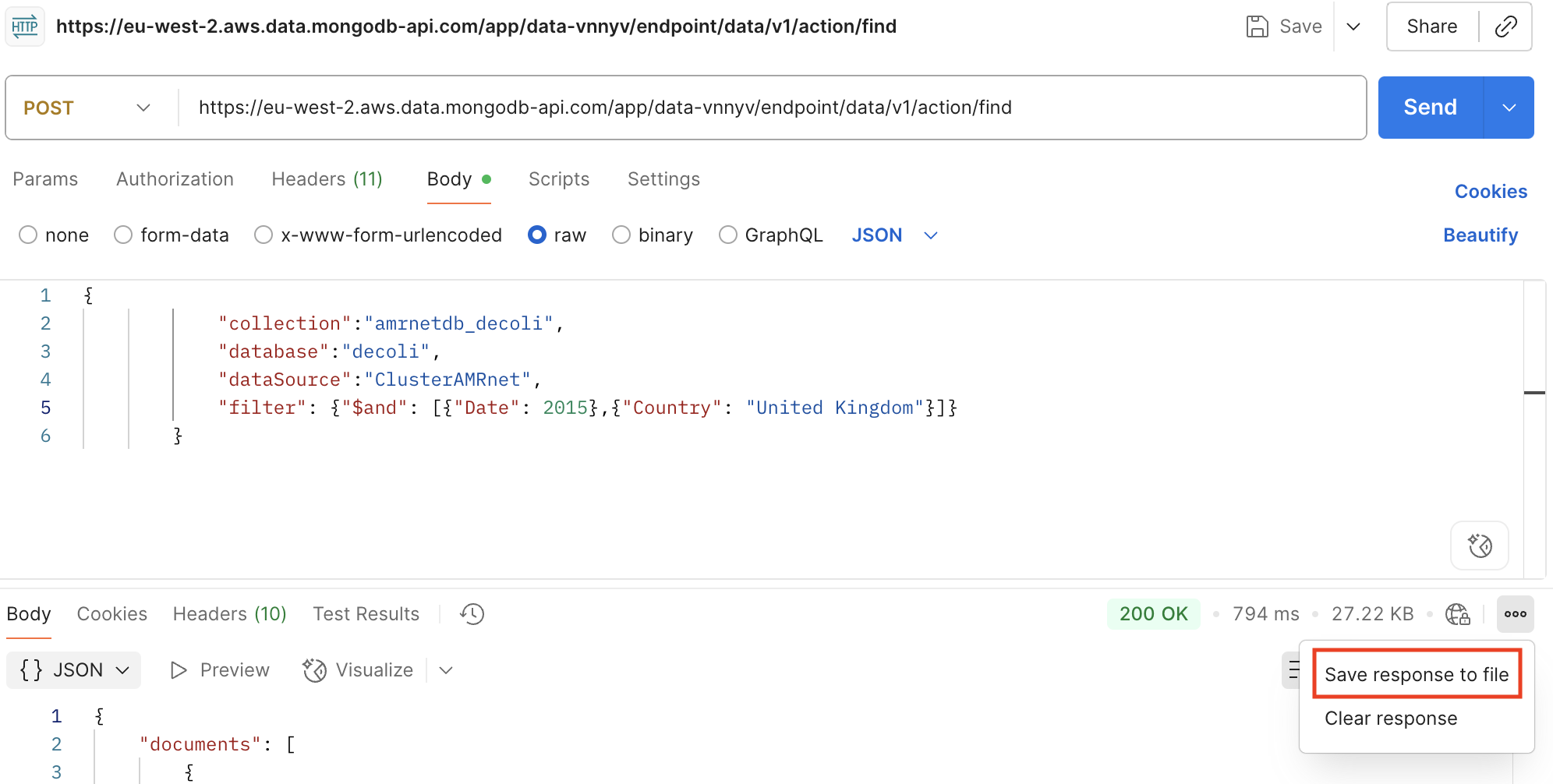
curl --location --request POST 'https://eu-west-2.aws.data.mongodb-api.com/app/data-vnnyv/endpoint/data/v1/action/find' \
--header 'Content-Type: application/json' \
--header 'Access-Control-Request-Headers: *' \
--header 'api-key: <API_TOKEN_KEY>' \
--data-raw '{
"collection":"<COLLECTION_NAME>",
"database":"<DATABASE_NAME>",
"dataSource":"<dataSource_NAME>"
}'
Código de ejemplo para descargar los datos con filtros Fecha y País para un organismo:
curl --location --request POST 'https://eu-west-2.aws.data.mongodb-api.com/app/data-vnnyv/endpoint/data/v1/action/find' \
--header 'Content-Type: application/json' \
--header 'Access-Control-Request-Headers: *' \
--header 'api-key: <API_TOKEN_KEY>' \
--data-raw '{
"collection":"<COLLECTION_NAME>",
"database":"<DATABASE_NAME>",
"dataSource":"<dataSource_NAME>",
"filter": {"$and": [{"Date": 2015},{"Country": "United Kingdom"}]}
}'
Código de ejemplo para descargar los datos con un solo filtro. ej. Fecha para un organismo:
curl --location --request POST 'https://eu-west-2.aws.data.mongodb-api.com/app/data-vnnyv/endpoint/data/v1/action/find' \
--header 'Content-Type: application/json' \
--header 'Access-Control-Request-Headers: *' \
--header 'api-key: <API_TOKEN_KEY>' \
--data-raw '{
"collection":"<COLLECTION_NAME>",
"database":"<DATABASE_NAME>",
"dataSource":"<dataSource_NAME>",
"filter": {"Date": 2015}
}'
Código de ejemplo para descargar los datos y guardar en JSON:
curl --location --request POST 'https://eu-west-2.aws.data.mongodb-api.com/app/data-vnnyv/endpoint/data/v1/action/find' \
--header 'Content-Type: application/json' \
--header 'Access-Control-Request-Headers: *' \
--header 'api-key: <API_TOKEN_KEY>' \
--data-raw '{
"collection":"<COLLECTION_NAME>",
"database":"<DATABASE_NAME>",
"dataSource":"<dataSource_NAME>",
"filter": {"Date": 2015}
}' > output.json
Nota
Para probar sus solicitudes cURL, puede utilizar la herramienta online Ejecutar comandos en línea. Esta herramienta proporciona una manera conveniente de ejecutar y probar los comandos cURL directamente en su navegador web sin necesidad de instalar ningún software adicional.
a. Línea de comandos¶
Para descargar datos usando nuestra API, por favor siga los siguientes pasos:
Una vez que tengas el token API, Reemplaza
<API_TOKEN_KEY>en el siguiente comando con el token de API real que recibiste.Determine la base de datos específica de la que necesita datos.
Abre tu interfaz de línea de comandos (CLI) o terminal y ejecuta el siguiente comando curl para descargar datos.
Si desea guardar los datos de respuesta en un archivo, puede utilizar la opción -o con curl. Este comando guardará los datos de respuesta en un archivo llamado data.json en el directorio actual.
b. Plataforma¶
Nota
Los usuarios tienen la flexibilidad de acceder a la API a través de su plataforma preferida. Como ilustración, proporcionamos orientación sobre el uso de la herramienta Postman para acceder a los datos a través de la API.
Pasos para importar el comando de ejemplo cURL usando Postman
Abre Postman.
Inicia sesión con tus credenciales y «descubre lo que un cartero puede hacer»
Haz clic en el botón «Importar».
Pega el comando cURL en la importación:
Revisa los detalles de la solicitud importada y añade
<API_TOKEN_KEY>enHeadersen Postman.
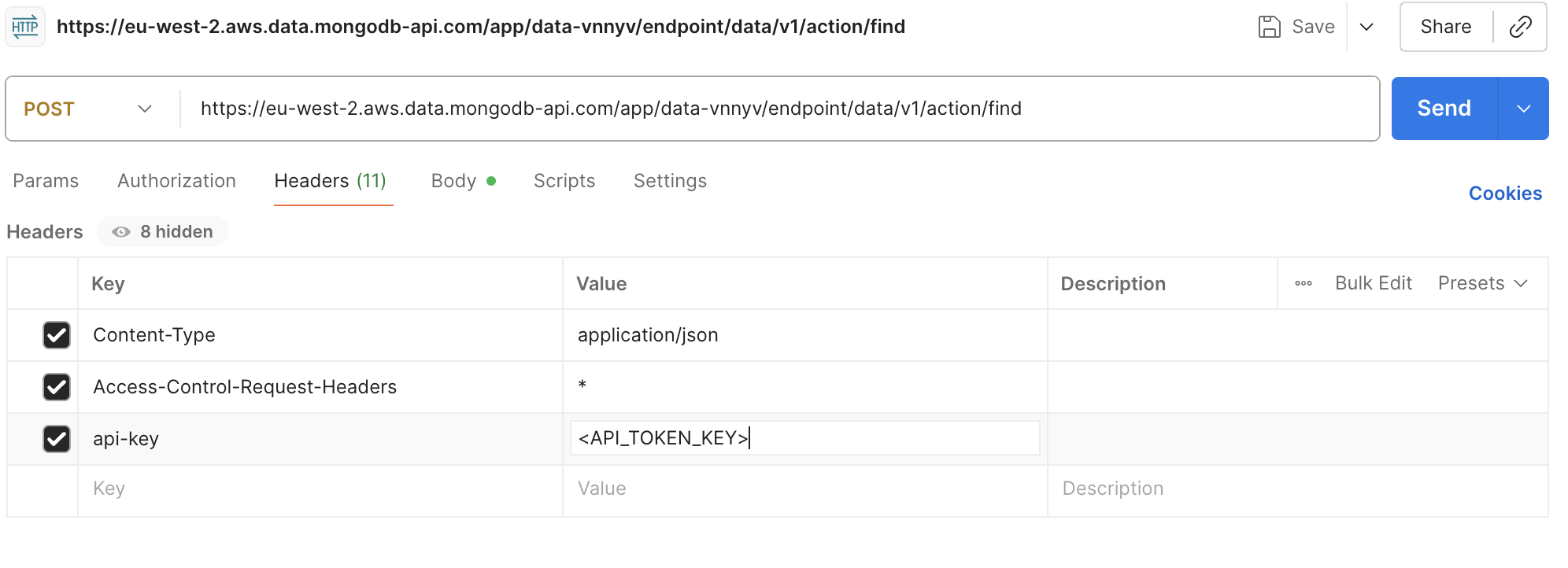
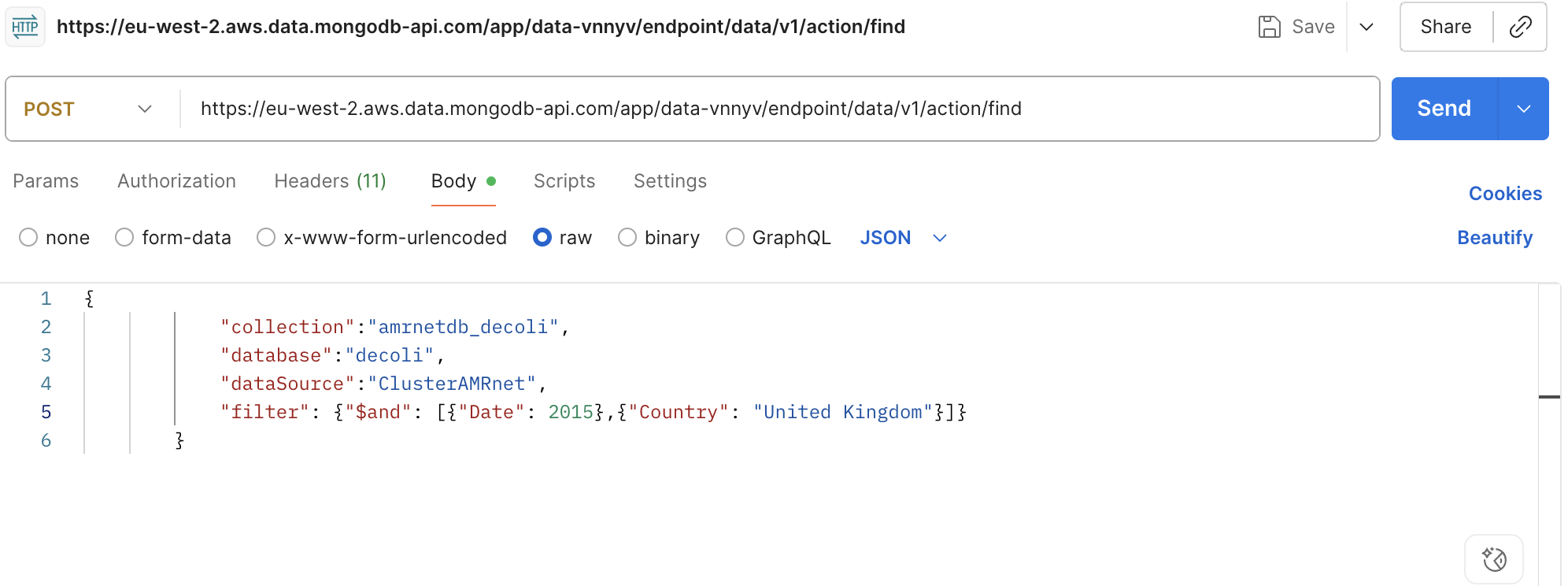
Reemplazar el nombre de la base de datos y el nombre de la colección basado en datos a descargar
Añade filtros para obtener datos específicos en
filter
Haz clic en «Enviar» para ejecutar la solicitud y ver la respuesta.
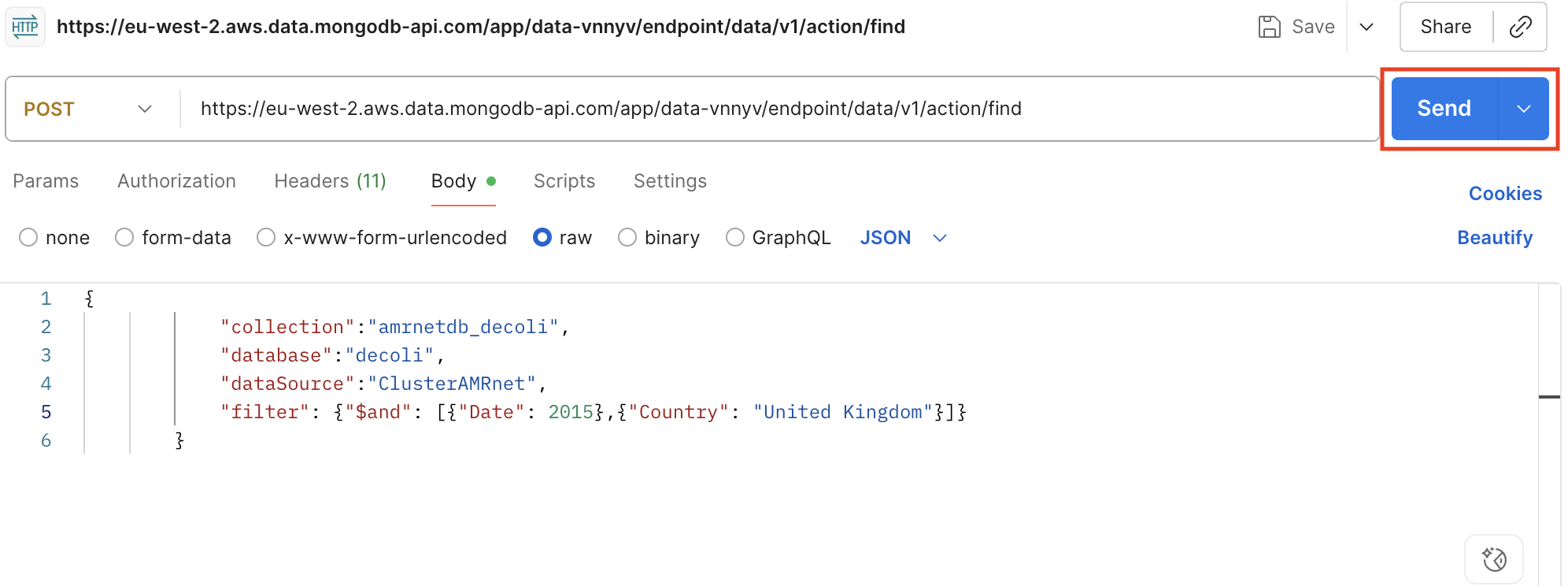
Guardar la respuesta en el archivo